Strongly Connected Components
| Tags | CS161Graphs |
|---|
Strongly connected components
When we are dealing with undirected graphs, anything we can reach with DFS or BFS forms a connected component. In other words, in this found tree, you can reach anything from anywhere.
However, in a directed graph, you form a connected component with DFS / BFS, but it is NOT the case that you can go from anything to anywhere. This is because there are one-directional roads!
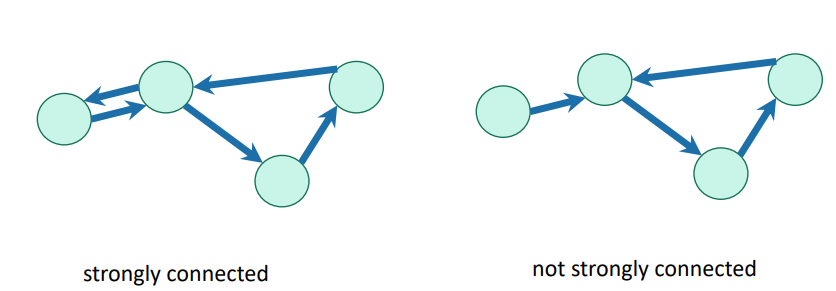
A directed graph is strongly connected if each pair of vertices has a path between them. A directed graph is weakly connected if when you remove the directionality, the graph is connected.
Technically speaking, the connected components must be maximal. So in the picture below, the four vertices are strongly connected as one, not as two components.
Applications
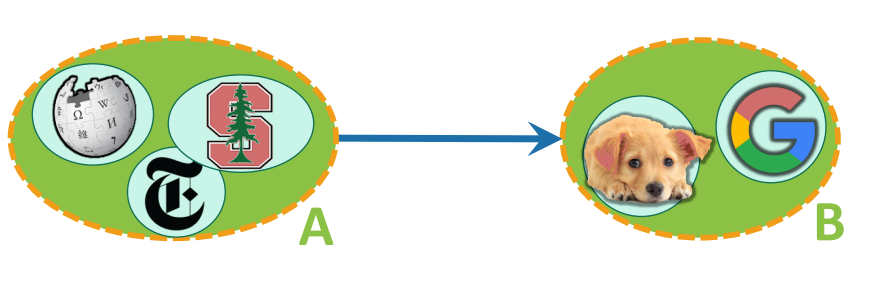
SCC’s (strongly connected components) are important because that’s a lot like how our internet works. We have a lot of websites that point at each other. Can we find a set of websites such that we can always reach all the other websites by clicking through websites in that set?
Finding SCCs the naive ways
- we could just decompose the graph in all the different ways and check if they are strongly connected. This is kinda stupid.
- We could take a connected graph from and run DFS a bunch from each in that subgraph. This is better, but it’s still . Can we do better?
Kosaraju’s algorithm
- Do DFS to make a DFS forest
- Reverse all the edges in the graph
- Do DFS again to make another DFS forest.
- Start with the vertices with the largest finish time
- The SCCs are the different trees in the second DFS forest.
The intuition, part 1
When you flip the edges in a subgraph that is strongly connected, it is still strongly connected. This is because between there exists two paths, . When we invert all the edges, the two paths essentially invert. The forward path now becomes the backwards path. So, essentially, we can find the SCCs on the inverted graph. But how does that help us?
Ok, well that’s interesting. But how does that help us? Well, let’s make an SCC graph.
The intuition, part 2
This SCC graph has nodes that are strongly connected components (i.e. an aggregate of nodes) and edges between them. This graph must be a DAG, or else we would be able to collapse the nodes into each other (any cycle means a path!).
Before you inverted the edges, the node with the latest finish time is the node that goes first in the topological sort, meaning that it has no arrows going into it. When you invert the edges, now there is no arrows going from it. Effectively, it “traps” the SCC such that your DFS is limited only to this scope (because again, flipping edges doesn’t change SCC).
And this keeps on going. If you invert the edge, you are essentially inverting the topological sort so the next node you do DFS search in will also be “trapped”.
This is a really neat trick!
The formalism
When we prove this algorithm, we want to show that by starting from the highest finishing time, we will be within a strongly connected component and be trapped in this strongly connected component once the edges flip.
To do this, we just want to show that in the original graph, if we start traversing based on the largest finish time, we would always encounter nodes that have all arrows pointing away. To help us with the proof, we are actually going the other direction. We show that all has finishing after . We are still using our idea of SCC graphs, in which each node is a strongly connected component. Our are both SCCs.
First, we will show that if in the original graph, then the finishing time of is after the finishing time of . To show this ,we consider two cases
- We reached before in our DFS. Let’s say that was discovered last in , meaning that . Let’s say that was discovered first in , meaning that . Then, we know that is a descendant of in the DFS forest. This mean that finishes after , which means that as desired.
- We reached before in our first DFS. There are no paths from to , so we must have explored after we restart the DFS.
So what’s the upshot? If , then the finish time of the SCC node will always be after the SCC node . Again, note that we are not dealing with individual nodes because that we have already proven.
Therefore, in the reversed graph, we have the child finishing after the parent (in the original scheme). Therefore, the largest finish time would have all arrows leading in (if there were an arrow leading out, then that arrow would lead to the larger finishing time). And this “traps” it.
Induction
We will finally prove that this method works by induction. Let’s say that the first strongly connected components have been extracted already.
Now, suppose that you get the next tree with root , which lives in some SCC . Because has the largest finish time, we know that all the arrows point to the SCC that is from.
Therefore, there are no edges leaving to the remaining SCC’s, so a DFS started at recovers exactly , which completes the induction to make the st tree.
Example uses
Largest “reach”
A “reach” is defined as the number of vertices reachable from one vertex. The naive solution is to run BFS on each vertex, but you can do better if you find all the SCCs (because all vertices are reachable within an SCC). Then, you order the components in topological order, and then you see, in reverse topological order, how many SCCs each component is connected to. Return any vertex in the component that has the most connections.
Formal solution
