Select Kth lowest
| Tags | AlgorithmsCS161 |
|---|
These sections allow us to look at algorithms and exercise our analytic powers in the process
The problem
Problem: find the kth smallest number in an array . This is a really neat problem but it is also a good exercise in recurrence relationships
Naive solutions
One idea
- find the smallest
- remove the smallest
- repeat k times.
This has complexity .
Second Naive solution
As another naive solution, we can sort the array and take the kth last number, which has complexity. Can we do better?
The lower bound
We know that it is at least , because we need to consider all the elements in the array at least once.
Moving towards the solution
What if we could discard half the array at a time? We can actually do this if we choose a good pivot and then split the array into elements below or equal to the pivot, and elements above the pivot. This process has complexity, so our recurrence relationship is
Which means that we can lower bound it to
and by the master theorem, we get that . Nice!
The algorithm


These are two equivalent expressions of the algorithm. One is a bit more interpretable. We subtract 1 on the last case because we exclude the lower half and the pivot from our search
The pivot
The hardest part is actually finding a good pivot algorithm ChoosePivot().
The best case scenario
Claim: if the pivot is always chosen to be the center, then it runs in time
Proof: We remove half of the elements each time, so , which from the master formula we know yields
This is what we alluded to when we first started the problem. However, to find the center, it’s equivalent to calling Select(A, n, n / 2), which causes infinite recursion. So as cool as this sounds, we can’t do this directly.
The worst case scenario
Claim: if the pivot is always the minimum or minimum element, then the function runs in time
Proof: We use a recurrence relationship. because the number of elements decreases by 1 to process. By rolling it out, we can say taht
With a different constant , we show that the opposite inequality is true. So we conclude that
Random selection
Why don’t we choose randomly? It’s actually a good idea! The expected runtime is and in most pivot-based algorithms like QuickSort, we just end up doing this because it’s the easiest. But for intellectual stimulation, let’s look at something a bit more complicated.
Median of Medians
What about using something “close enough?” Let’s introduce the Median of Medians algorithm, which is shown below

The idea is simple
- make groups of 5
- sort these groups. Individually, the sorting takes because there will always be 5 elements. So the sorting process is , because the groups depends on
- Make a set of all the medians of the groups
- Find the median of this group recursively.
Bounds of Median of Medians
We can actually prove this fact: , and . Here’s the proof sketch
- is our partition. It is greater group medians. In each of the medians that beat (except for the remainder group), it is implicit (due to the first median) that beat out of the numbers in each group. Therefore, is greater than at least elements
- As such, we the number of elements greater than is upper-bounded by , which when simplified, becomes . Neat!!
By symmetry, we can argue the other way around and show that the same property holds for the number of elements less than
Analyzing the complexity
So every step we take -ish steps to get the pivot, and then we are bounded by for the next partition. When , then we can say that this runs in constant time (i.e. we can add an additional base case to the above algorithm such that at low enough array sizes, we just do brute force sort and index to find the k-th smallest. This yields the following:
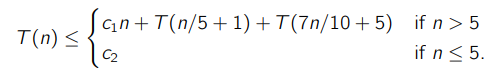
Inductive substitution method
We want to prove that it’s in linear time, so let’s postulate that for some and .
This becomes our inductive hypothesis, and we are ready to induct. Note how we use our strong inductive hypothesis to drive the computation forward
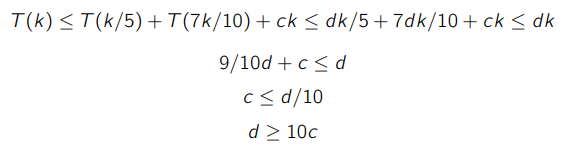
At this point, you show that this does exist, which is sufficient. Now, for the formal proof, just go back and let and show why it works.