Hashing
| Tags | CS161Datastructures |
|---|
Hash tables: the big idea
We want to have a datastructure that can take in incomparable objects and store them such that the average insert, delete, and search operations are . Of course, there is no free lunch; the worst case is
To be more precise, we want to avoid collisions. The more you collide, the slower the process becomes.
To do this, we have hash families. A hash function is a deterministic function, but we can sample from a hash family at random. We will come back to this later. We want to sample from a universal hash function
Details on implementation
A hash table is just a map whose key is the value placed through some deterministic hashing function. If there are intersections, there are two options
- Use a linked list and add all intersections to a linked list
- Use an open addressing plan and bump the intersection to the next open array index
Details on complexity
When we say that the hash function has complexity, we mean that over all the hash functions that we can sample, the average number of elements per bin is a constant number.
Working towards hash tables
- We could just try using the element values themselves as the address. This would definitely yield search, insertion, and deletion but it takes a ridiculous amount of space
- We could try something easy, like constantly using a digit of the number as the address. The problem here is an adversarial agent. By knowing the hash function, it is possible to game the system and yield the worst-case scenario
- ⇒ The key upshot is that no deterministic hash function can beat the adversary. When we say “deterministic,” we mean that there is only one hash function we choose. All hash functions are deterministic but we can have the options of choosing a random hash function from a pool of functions
Formalism
Let be a universe of size . This is absolutely huge. At most keys will show up, and we would like to map each to a unique bin as it shows up.
The Hash Function: an intro
The hash function can be viewed as a sort of mapping function that turns a distribution into a close of a uniform distribution as possible. So if we knew that the keys are random, then we can just compress the keys down into the appropiate bins, no questions asked. The reason why we can’t do that is because often, our keys are not uniformly distributed, and what’s more, an adversary can intentionally change the distribution.
Analyzing hash functions
Define the indicator random variable . This implies that the is random, because the inputs are not! For universality, we want to show that , where is the number of buckets (see more details in the later section) for all
The number of keys that end up in the same bucket is just
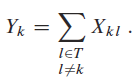
So a good hash function will satisfy this constraint on the number of keys per bucket
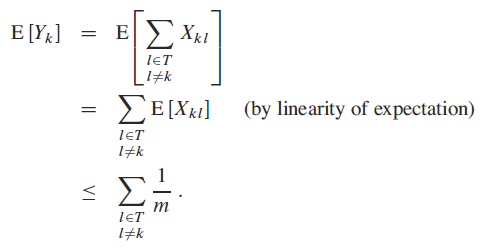
Zooming out again
So we are taking the expectation across all possible hash functions. Again, hash functions are deterministic so we are not taking it across a specific hash function. If they are not random, then an adversary could find out which items intersect, and then continuously feed those elements.
Random hash functions
Hashing can be seen as a sort of game in which the adversary chooses any items and then you choose the random hash function. The adversary knows all about the process but has no control over the random selection. This is a little different than our saga on randomized algorithms. We were allowed to control the randomness then, because we wanted to look at what’s the worst case scenario. In this case, we care more about how the elements are added, not about chance itself.
Uniformly random hash function
Again, hash functions are deterministic. However, if we see the function where is the universe and are tha hash buckets, we can randomly assign elements in to to generate a hash function.
In fact, this is our first hash function. For every possible input in , just assign to uniformly at random.
We can analyze this using the framework above. So let’s look at an arbitrary input . In , the input contributes one element (duh). When we hash all other values, each has a chance of hashing into the same bin. So we get
Because this is a constant number that doesn’t depend on , it is a universal hash function!
The problem
So the uniformly random hash function is nice but it has one huge problem. To sample a hash function from it, we need to define the mappings for all of , which is incalculably hard.
Hash families
There are a huge number of hash functions. In fact, there are different hash functions. But can we pick a smaller family of hash functions such that the expectation still holds. Families that have this property is a universal hash family
Again, we want to be careful here. Underpinning everything is the idea that the adversary picks the numbers before you decide the hash function randomly. So the expectation is under adversarial choice. As such, you can’t just define a subset of hash functions randomly and hope it works.
Universal hash family: proving
We want to show that , where is the number of hash buckets. This is derived from the indicator variable . In essence, we want to show that, regardless of how the adversary picks the numbers (hence the “any ”), the chances of collision stay the same upper bounded by .
Example of when this is not the case
Why isn’t the hash family where you either hash by most significant digit or by least significant digit a universal hash family? Well, remember that an adversary can attack! They can just pick numbers that have the same first and last numbers
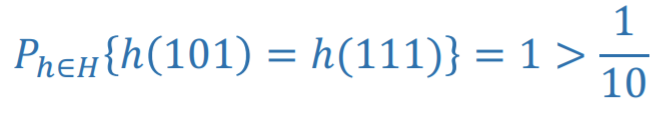
Here’s the key steps
- Adversary knows everything
- Adversary picks the numbers
- We pick the random hash function and compute the chance of collision
In general, if there is a flaw in the hash function, you might be able to product a counterexample that hash to the same bins no matter what funtion parameters you end up picking. This can become your new set, which means that , which is much higher than
Tractable universal hash families
The key problem is as follows: how can I make a hash function in which we scramble everything up so uniformly such that the intersection probabilities are the same as a uniformly random function, without the need to manually assign each mapping?
Prime hashing
Let be a prime number. Let
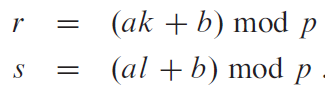
where and is larger than the size of the universe where is chosen from. Now, given some , we know that the map to distinct . This is because
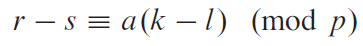
And none of the right hand side is 0 in mod p space, so the product must also not be zero. This is why we say that . The key upshot is that we have created a bijective function in mod space.
However, this means that we are able to solve for as the following
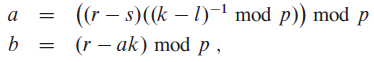
This means that given some , each has a one-to-one correspondence with . As such, the probability of intersection is just
Now, we take another where is the size of the hash table. Intuitively, it’s like ‘coiling’ up this new number mapping into a circle. You want to find the probability that . Now, given any choice of , there are choices of that are equivalent . Just think about it for a second. And because we’ve established that are determined bijectively by , we can calculate the chance of intersection in terms of .
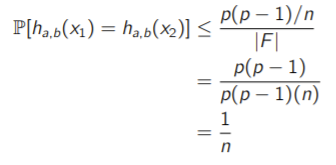
Because the probability is at most of intersection, we conclude that this is a universal hash function, as desired.
Challenge questions

The answer is because there is at least one hash function that does this, due to the pigeonhole principle.