Dynamic Programming Examples
| Tags | CS161Examples |
|---|
Recipe
- optimal substructure (hardest)
- recursive formulation
- dynamic programming
- bookkeeping (for reconstruction’s sake)
Tips
- Start with a solved largest problem. What can you guarantee about a smaller problem? (think: subpaths of an optimal path)
- Look at the full problem and think about how you can boot the computation to a smaller problem by splitting it into cases
- Start with a solved smaller problem. How can you make it larger.
- look for “paths” that allow you to express something complicated through iterations of recursion.
Longest Common Subsequence
Simple task: given two strings of length , find the longest subsequence that they share in common. A subsequence is formed when you remove characters from a string
Optimal substructure
Here, we rely on one key insight. Look at the last character of both strings.
- If they are the same, then this last character is necessairly part of the longest common subsequence
- If they are different, then at least one of the last characters is not part of the longest common subsequence, so you can essentially chop off the last character. But which one? Well, that you don’t know. You must find out by trying both!
Recursive formulation
Let’s use a table to keep track of our results. In top-down recursion, the table would just be a recursive call. However, today we are focusing on bottom-up solution approaches. As such, we define to be the longest common subsequence with strings where is the prefix of with the first characters, and same deal with .
If , then
What about if ? Well, you’ve got some exploring to do!
The two components essentially try the strings with one character removed. Implicitly, it also tries the the strings with both end characters removed, in the next step (just roll out what is equal to)
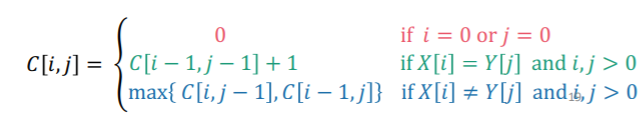
Dynamic programming
You start with the base case, and then you build up the table row by row. At element , you apply the recursive rules that we defined above. This either means adding one to the diagonal, or picking the maximum from the left and the above cells. This would be a bottom-up programing algoriithm
For a top-down programming algorithm, you would make a recursive call every time you wanted to find the of a smaller problem, but you would keep track of a table and short-circuit the recursion if you find that it has already been solved.

Bookkeeping
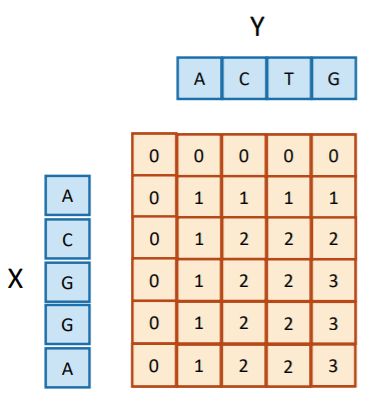
Now, how do we reconstruct the LCS from the table? You can use the naive approach, which is to keep track of your string as you go. However, this does have a high space complexity.
To mitigate this, you can use a clever backtracking strategy. The lower right corner of the table is the answer you get when you call (i.e. with the whole string). Now, you apply the following algorithm on the table
- Look at . If they match, pick this character and move diagonally.
- If they don’t match, find the element that was copied to the current element. This is either above or to the left. Go there, but don’t pick any characters. If there are ties, your choice doesn’t matter.
When you reach any , you have reconstructed the LCS (albeit backwards).
Complexity analysis
To fill the table, we need steps. If you are not concerned with the final answer, we can actually skip the table and just keep the last two rows in each iteration of the algorithm, because the decomposition never goes before or .
Challenge problem
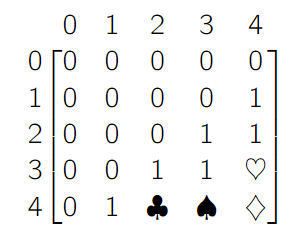
is the rows and are the columns. What can you say about vs ? Well, you can use the following chain of logic
- We know that because that’s a one surrounded by zeros
- We know that because of similar reasoning
- However, we know that because it’s a zero. Therefore, there is no equality ‘bridge’ between and , meaning that .
You can do the same reasoning pattern for the symbols to figure out the rest of the matrix.
Knapsack problem: unbounded knapsack
Given items with with weights and values , what’s the most value I can get with a capacity of ? Let’s start with a simple iteration of the problem, which assumes that you are in a warehouse and can take as many things of item as possible.
Subproblem decomposition
If you have an optimal knapsack and you take away an element, this smaller knapsack must also be optimal for that size. This is because if it wasn’t optimal, then you can add that element back into the true optimal smaller backpack and create an even more optimal original knapsack, which is a contradiction.
Therefore, if you have a capacity , the optimal packing is the best you can make , plus a new object . You have multiple objects, so you must try them all.
Recursive Formulation
So, if you define an array such that is the best possible value for a specific weight , you can define the relationship as
If there is no such such that , then .
Dynamic programming
You can just use this recurrence relationship to build a bottom-up algorithm

Challenge problem
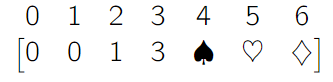
What can we say about this?
- Because is the first knapsack that has non-zero value, we conclude that there is one object of weight 2 and value 1
- Because there are no objects of weight 1, we conclude that there must be one object of weight 3 and value 3
- Therefore, the minimum value of the knapsack at weight limit is just , because you can just use the knapsack of weight . It’s a minimum because we don’t know if there is a weight 4 object.
- We can also say that the minimum value of the knapsack with limit is 4, becuase we can add the objects of weight 2 and weight 3 together .
- We can also say that the minimum value of the knapsack with limit 6 is 6 because you can add two objects of weight 3 together.
Knapsack Problem: 0/1 Knapsack
Here, we have a small problem. Previously, we were able to do and find the best thing to add. However, if we can only take one of each item, we can’t blindly optimize. We must formulate a different solution.
The insight
If we are given the use of the first items, we can either choose or not choose to use the item. If we don’t choose the item, then we default to the optimal bag that has the same capacity but operating on the first item. If you choose the item, then you reduce the capacity and you look at the optimal bag with reduced capacity on item.
This sounds like a job for...2D array!!
The setup
let be the optimal value at capacity with the first items available.
The code

and this is what it looks like in tabular form
Independent Set
An independent set in a graph is a set of vertices such that no pair has an edge between them. We want to find the independent set with the largest weight. The original question with the random graph is actually NP complete. So that’s no good. Let’s try a tree!
Hmmm. Let’s use the strategies that we’ve learned so far and see where they can take us. Let’s try building things up. A tree can be split into subtrees. In each subtree:
- the root can be selected. Then, its children can’t be, but the children of those children are just more subtrees
- The root may not be selected. Then, its children are subtree problems.
The approach
Keep two arrays. Let be the weight of a maximally independent set rooted at node , and let be the sum of weights of the children at , assuming that is not selected. Technically, this distinction is not necessary but it helps for notation. As such, you have
Note how the first term is when the root is not selected, and the second terms is when the root is selected.
Dynamic programming
Here, we actually use a sort of bottom-up approach, even though we use recursion to get to the leaf nodes. This is because we need the children (base case) to be filled before we make our way up. It’s still bottom up.

This is different from recursive divide and conquer because you are taking advantage of overlapping subproblems!
Because you only fill up each entry once, the complexity is . Nice!
Binary numbers
What is the number of binary strings of length you can make such that there are no repeated ’s?
- Key insight: no matter what, we can take the previous string and add one.
- Second key insigth: no matter what, we can take two strings before and add .
- Third key insight: we can’t add , because that’s covered in the first insight. We also can’t add because that might be illegal
So, you make where is the length of the binary string. We have
with a base case of and .
More examples

- Store a table where is the maximum product you can make with length . Then, compute the max of , where . Build bottom-up

- recursive insight is that on a 2d grid, we look at all the places where in one hop, a knight can end up at the target location. Add those up.
- To do this, start with an array of zeros, and for each element, look at the knight-neighbors (locations that are reachable by one knight hop). Then, add them up and do this for all of the elements. At the end, you just need to return .