Bucket sort
| Tags | AlgorithmsCS161 |
|---|
Sorting paradigms
When we think of sorting, we must ask ourselves, “what is the input, output, and the operations allowed?” Depending on these answers, we might different limits on how fast we can go.
Bucket sorting
‘But it is true that we can get a better complexity if we change the assumptions up a bit. Now, what if we are dealing with “nice” integer numbers from ?
Counting sort
- Make an array of size
- Go through the list and tally up the presence of each number in the appropriate array index
- At the end, read off the array of size and for each element , output with a repetition of .
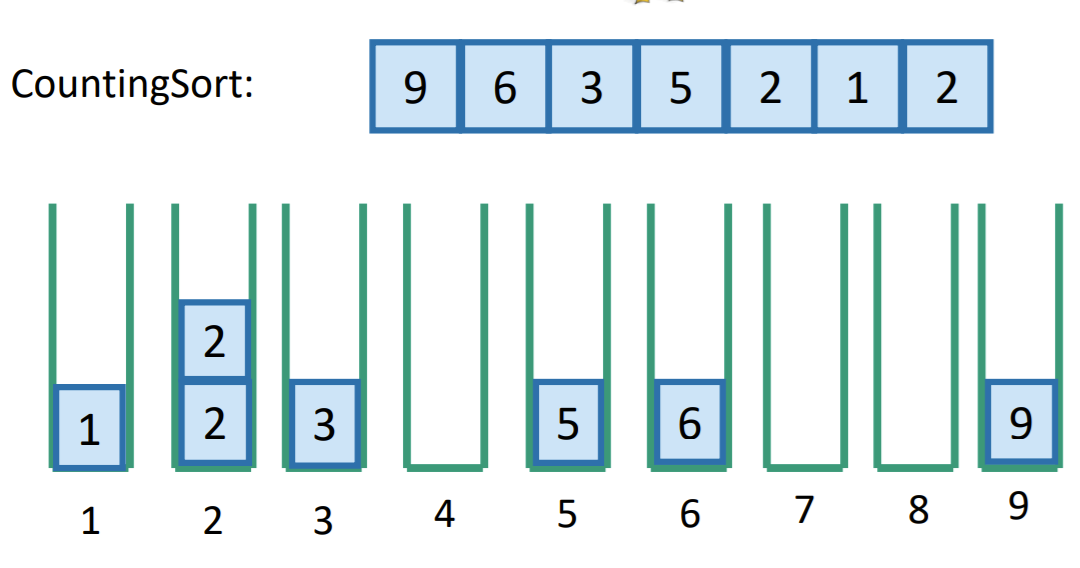
This is a really micro brain sort but it actually works in time! However, there is a pretty big downside. If is very large, you will have problems. And it is typical that is larger than the list size , lest you repeat values.
Radix sort
This is a modification to counting sort that actually works decently.
- Run bucket sort using the least significant digit
- recombine into a new list
- repeat step 1 but you use the second least significant, third least significant, etc. When you get to the end, the recombined list is the sorted list
- if you encounter the end of some number (i.e. you are sorting 100, 2, and 45), just pad with zeros
Radix sort proof that it works
Here’s a proof by induction on a list with values where each is a digit. Our inductive hypothesis is that at step , the elements are in sorted order, hierarchically. This means that if , then it comes before . If these elements are equal, then we break the tie by looking at , , and so on. Intuitively, this ordering comes about from the stable concatenation operation and the reverse significance sorting order.
- Base case: there is nothing done, so our inductive hypothesis is vacuously true
- Inductive case: after sorting by , the first part of the hypothesis comes true automatically, in which if , then comes before in this next list. If , then the previous ordering is kept, in which if , it is true that comes before . Again, we keep the previous ordering because we move through the list from left to right, so if two things sorted at go into the same bin, the one that got read first will be placed into the bin first. Therefore, our induction is complete!
Radix sort complexity analysis
So let’s start simple. If you have digit numbers, the complexity is , or . Hey, this is cool. But wait...
If in the list of size you will have numbers from , then . And suddenly our complexity becomes . Ooops...
But wait! We can change the base! We calculate by doing , where is the base that we bucket in. The larger the , the more buckets but the fewer digits to sort. For some intuition about the definition of , think of and . The log is below 1, but we do have one digit. Therefore, we take the floor and add 1.
Let’s put this together. Let be the maximum number, and be the base. In each sort, you need to look across numbers and initialize bins. This yields
How do we choose ? Well, we can let , and now we get
We pick because we want as large of an as possible, but if we make any larger than a scalar multiple of , then it will contribute a polynomial factor to the sort, which is not good.
If for some finite constant , then we have complexity. However, if , then we have , which is pretty bad.
(as a sidenote, we don’t drop the because it still is related to when you distribute, and in the original expression. It’s important to be careful of these things!)
Challenge questions involving lower bounds

If this algorithm existed, then you can do a divide and conquer sort such that
If we just roll this out, we can kinda see that we add for times, where is the number of times you need to apply a logarithm until you reach . This we know as . However, it means that we can sort in time, which is impossible using comparison-based sorting.

Why is this impossible? Well, if we can do all three things, we can just add an unsorted list in time, and then pluck out the smallest objects in time, yielding an complexity sort that would violate our previous proof of the lower bound of .